
S V
Author's posts
Jan 12 2026
Ghost of the LHC 1K

This is a quick small 1 kilobyte intro to support the R-Sync 2026 demoparty in Belgium. It was shown in the PC demo compo, and took 3rd place.
You can run it yourself (if you have a modern Nvidia card) : Download Remember that anti-virus programs might not like the crinkler compression and other tricks to make this below 1 kilobyte.
If you prefer to watch it on Youtube: https://youtu.be/G3jO5JqarDw
Aug 06 2025
Bones of Civilisation 1K shader code
This is the exhaustively documented shader code of the Bones Of Civilisation 1 kilobyte intro. Remember, don’t try this at work!
Continue readingAug 02 2025
Bones of Civilisation 1K

This is our contribution to the Assembly 2025 1K intro competition. It placed 1st out of 3 entries. feedback is welcome on the Pouet page: https://www.pouet.net/prod.php?which=104610
You can download the executable from here: Bones-Of-Civilisation-by-Fulcrum.zip Warning: Windows Defender doesn’t trust the 1K executable and will happily delete it (the executable header trickery makes it claim it’s a virus), so download it in an excluded folder. Or you can watch it on YouTube .
Feb 20 2025
Spirotranquil 1K

This 1K intro was made for the LoveByte 2025 high-end 1K intro competition, it placed 4th.
The effect is a particle effect based on the spirograph toy I had as a kid. The music is again procedual floatbeat on the GPU, but this time I wanted to see if I could add explicit synchronisation between the visuals and the music. It works, but takes quite some bytes so the visuals couldn’t be very complex. Also, the first time the shader is compiled, the intro might get out of sync. So best to press escape and restart it to be sure sync is as it is supposed to be…
You can download the intro from here: Spirotranquil by Fulcrum
Beware, Windows Defender is once again paranoid and likes to delete the .exes as soon as it sees them. Best to unpack in a folder you’ve excepted from the AV.
Aug 10 2024
Building From Bedrock 1K shader code
This is the exhaustively documented shader code of the Building From Bedrock 1 kilobyte intro. Remember, don’t try this at work!
Continue readingAug 03 2024
Building From Bedrock 1K

This intro was created for the Assembly summer 2024 1K intro competition, where it placed 1st. Since this was the first time one of my kids came along, I was inspired by one of their favourite games :) The music was made by Miss Saigon on a very limited size and time budget.
You can watch the intro on Youtube here: https://youtu.be/yDIRSU-8coQ
For feedback, the Pouet page is here: https://www.pouet.net/prod.php?which=97442
If you have a fast enough Nvidia video card, you can run the executable yourself, download it from here .
Warning: Windows Defender doesn’t like the 1K assembler magic that is needed to create this, and will report it as a virus (and delete the exe). You might want to download it in a folder that is excluded from the virus scanning.
Aug 03 2024
Lux Minima, Lux Sancta 1K

This 1K intro was made for the Lovebyte 2024 1Kb intro competition, where it placed 4th. It uses a particle effect, instead of the usual raymarching :) This also means that you don’t really need a heavy videocard to run this. It’s recommended to run the intro realtime, because the Youtube compression really messes up particle effects… You can download the intro from here, feedback welcome on the Pouet page. Note that antivirus scanners might complain about 1Ks due to the unusual header hacks used.
If you prefer to watch it on youtube: you can do that here.
Aug 03 2024
Pyrotranquil 3K

This is a small intro (less than the usual 4K) using particles and compute shaders. It took part in the R-sync 2024 demoparty in Belgium, where it took first place in the combined demoparty. I was trying to make an infinitely-running demo like Timeless/Tran, but due to numerical precision the effect starts to look a bit weird after 7-8 minutes.
You can watch a HD recording on Youtube , feedback welcome on the Pouet page
Or you can download an run the intro yourself: Pyrotranquil by Fulcrum (HD)
Aug 03 2024
Creative Carving 1K

This done-in-a-hurry 1K was made for the Demosplash 2023 combined intro competition, where it placed 1st. It’s based on a recursive torus idea that I had for quite a while, with some added near-Halloween styling.
You can watch it on Youtube , feedback welcome on Pouet
Or you can download the executable and run it yourself: Creative Carving 1K by Fulcrum
(Standard disclaimer about antivirus not liking 1K intros applies)
Aug 05 2023
Lost in Neon 1K
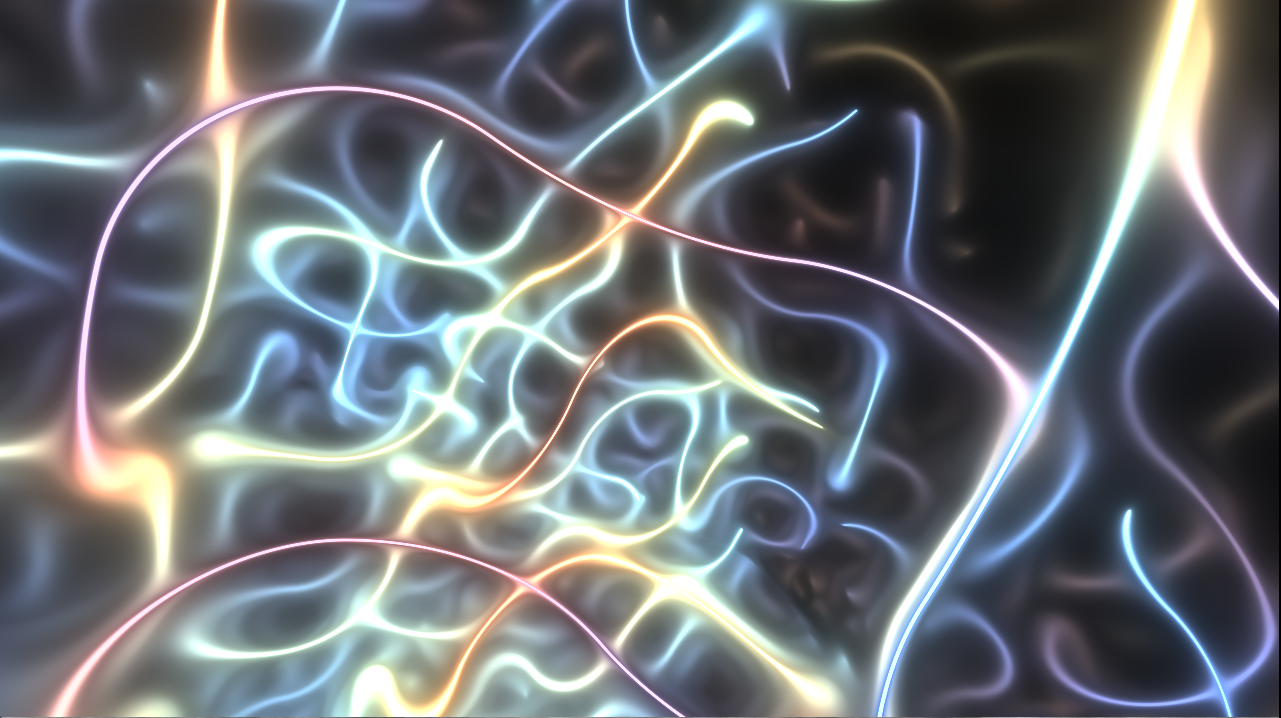
This is our contribution to the Assembly 2023 1 kilobyte Intro competition, where it placed 2nd.
Get the executable here: Lost In Neon by Fulcrum
You can also watch it on Youtube